


polysome profil
ing 富集检测 ¥6800
广州卿泽生物科技有限公司
入驻年限:5 年
- 联系人:
吴小姐
- 所在地区:
广东 广州市 黄埔区
- 业务范围:
医疗器械、体外诊断、论文服务、细胞库 / 细胞培养、试剂、技术服务
- 经营模式:
经销商 生产厂商
推荐产品




公司新闻/正文
eLIFE. | Poly-Ribo-Seq技术揭示了小开放阅读框的广泛翻译
人阅读 发布时间:2024-04-24 09:50
导读
人类基因组中存在着数千个具有编码小肽(<100个氨基酸)潜力的小型开放阅读框(smORFs)。然而,实际翻译的smORFs数量及其分子和功能作用尚不清楚。
本研究中,作者通过对果蝇的多聚体(Polysome)部分进行核糖体分析(ribo-seq),从全基因组水平对smORFs翻译进行了评估。作者检测到两种类型的smORFs结合多个核糖体,从而进行活跃性翻译:
本研究表明:数千个smORFs在后生动物基因组中被翻译,它们是基因组中一类丰富且基本的组成原件。
文章索引
标题:Extensive translation of small Open Reading Frames revealed by Poly-Ribo-Seq
发表期刊:eLife
发表时间:2014.08
作者团队:英国苏塞克斯大学生命科学学院Juan-Pablo Couso团队
IF:7.7/Q1
DOI:10.7554/eLife.03528.
研究概览

研究结果
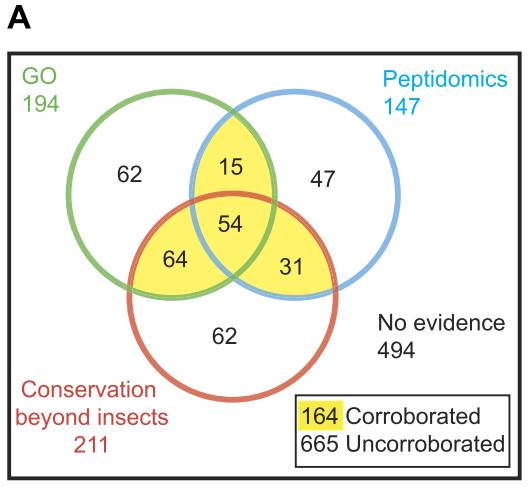
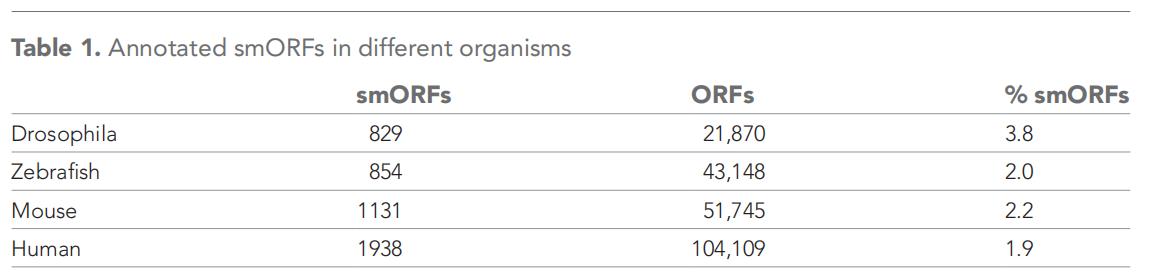
果蝇基因组的注释中,预测smORFs编码基因的比例是其他后生动物基因组的两倍(约829个smORFs基因,占总数的4%)。但只有164个带注释的smORFs具有以下表明翻译或肽功能的特征:(1)GO分析表明其具有蛋白质功能;(2)与蛋白质组学实验中的肽匹配;(3)编码序列具有保守性(图1A)。

为了特异性地富集活性翻译含有单个smORFs的mRNA,作者考虑到了smORFs的有限长度(≤303 nt)可结合核糖体的特点。据报道,1个核糖体占据80 nt。因此在smORFs上,核糖体的最大数量为5(起始密码子上一个,每80 nt一个)。qPCR证实:与large polysome相比,small polysome中的smORFs mRNA更丰富(补充图1A),但这表明果蝇的smORFs可以被多达6个核糖体结合,这可能反映了核糖体更紧密的分布。

因此,作者选择分离Fraction 2-6以富集smORFs。这些small polysome也可以结合典型的较长ORF的mRNA,这些ORF不会被核糖体完全覆盖,因此翻译的水平低于最高水平(补充图2)。

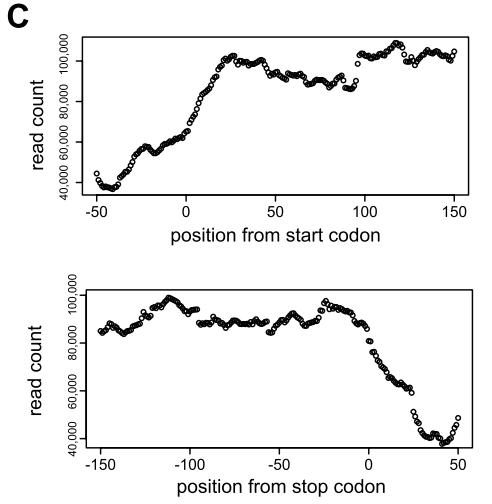
作者分别对large polysome和small polysome部分进行核糖体分析,并将胞质mRNA进行RNA-seq作为对照。分析显示:Poly-ribo-seq捕获了活跃翻译区域,因为约80%的reads映射到典型蛋白质编码基因的编码序列,读取密度在起始密码子之前和终止密码子之后下降(图1C)。
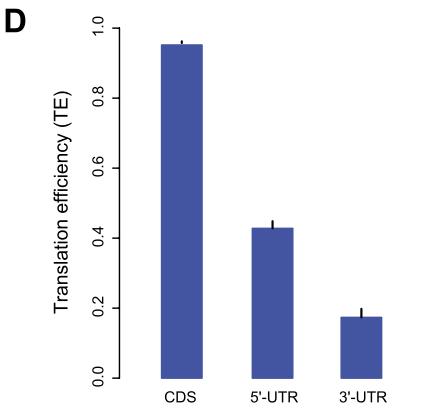
作者还分析了翻译效率(TE,即核糖体足迹的RPKM /总mRNA的RPKM)。与5'-和3'-UTR相比,CDSs中所有带注释的蛋白质编码转录本的TE中位数明显更高(图1D),这表明“Poly-Ribo-Seq”定义了活性翻译区域。

在第一次的Poly-Ribo-Seq实验中,共有191个带注释的smORFs被认为是翻译的。占S2细胞中转录的smORFs的约70%(图2D)。随后,作者对small polysome进行了重复实验,检测到224个smORFs的翻译(图2D)。因而,两次实验共检测到227个smORFs的翻译,占S2细胞中转录smORFs的83%(图2E)。在两个独立的Poly-Ribo-Seq实验中,核糖体密度的全基因组分布是强相关的(R2= 0.83),这表明Poly-Ribo-Seq具有很高的可重复性(图2B)。
第三次重复实验中,作者加入了去除rRNA的处理,因此增加了检测到的ORF总数,但只将推定翻译的smORFs数量增加了一个(图2D)。三个独立实验的结果高度重叠(图2D)。这些数据表明:在S2细胞中转录的274个smORFs中,有228个被翻译(83%),这与标准长度蛋白质编码ORF的翻译比例(81%)非常相似(图2E)。
检测小肽需要特定的肽组学方法。作者对S2细胞中大小为5-15 KDa的小蛋白进行质谱分析,以寻找smORFs肽(45-130 aa)。共检测到60个带注释的smORFs肽,其中40个在Peptide Atlas S2数据集中未检测到(图2F)。
接着,作者进行了肽标记转染实验。将smORFs编码序列的C端带上去掉了起始密码子的FLAG标记,因此任何FLAG信号都是smORFs翻译的结果。
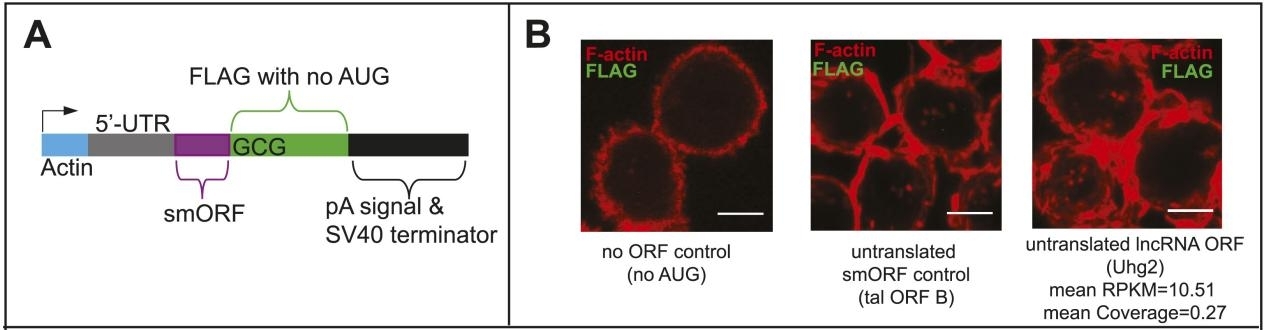
转染S2细胞后,观察到12个smORFs的翻译,它们表现出一系列的翻译指标(图3A-B)。标记肽表现出不同的亚细胞定位,这表明不同的肽功能(图3A-B)。

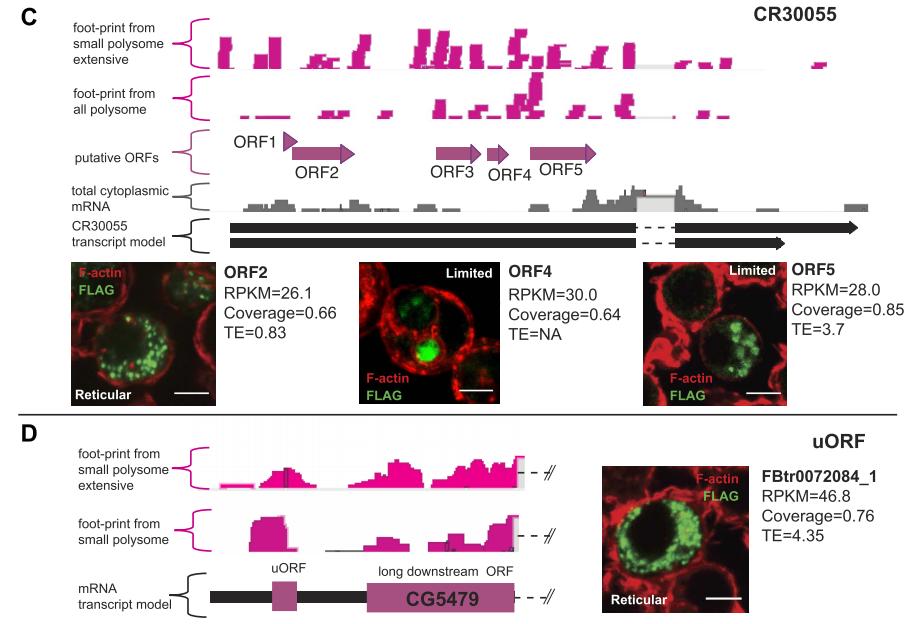
另外,还有上游短ORF (uORF)。作者在28,529个FlyBase注释转录本的11,587个5'UTR中鉴定出14,881个带有AUG起始密码子的uORF。其中9069个uORF在S2细胞中被转录,其中2708个(30%)被核糖体覆盖(图2E)。但它们编码肽的丰度较低。然而,uORF的标记偶尔会显示出与已标注的smORFs相似的信号(图3D)。
进一步地,作者研究了翻译后的smORFs的氨基酸组成,与常规长蛋白和氨基酸随机使用进行了比较(图4B)。注释的smORFs显示精氨酸的使用低于随机使用,也显示出几种氨基酸的不同使用,如富含赖氨酸和苯丙氨酸,而缺乏丝氨酸(图4B)。这些氨基酸是典型蛋白质中α -螺旋的特征。在翻译smORFs(图4C)和所有预测的smORFs中(图4D)均大约三分之一存有大量假定的跨膜α-螺旋基序。
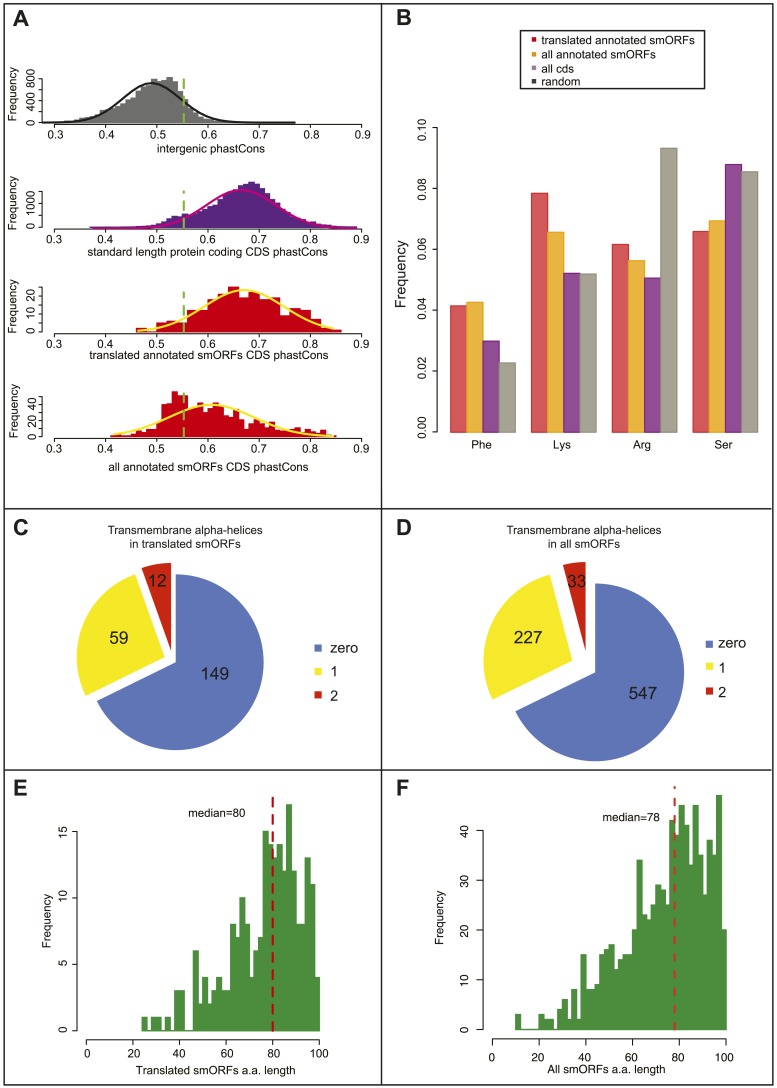
Poly-Ribo-Seq检测到的翻译smORFs的生物信息学特征,包括:氨基酸用量(图4B)、推测的跨膜α -螺旋的丰度(图4C-D)和平均肽长度(图4E-F)。
由于uORF和ncRNA编码的肽在生物信息学上与smORFs和标准长CDS不同,因此暂时没有指标能够将翻译的uORF和ncRNA与基因间序列或随机序列区分开来。
因此,Poly-Ribo-Seq应该可以检测两种类型的smORFs的翻译:
研究结论
本研究表明:数千个smORFs在后生动物基因组中被翻译。而且,存在两种类型的翻译smORFs。“较长”的smORFs产生保守的80个氨基酸长的肽,其翻译效率类似于典型蛋白,其功能倾向于与细胞膜相关。“较短”smORFs主要存在于5'UTR和非编码RNA中,基因预测程序无法检测到,平均编码约20 aa长的肽。它们也不太保守,翻译效率较低,功能尚不清楚。
欢迎致电了解详情或咨询!
广州卿泽生物科技有限公司
地址:广州市黄埔区伴河路96号一栋三层321房
电话:18925086102(微信同号)
人类基因组中存在着数千个具有编码小肽(<100个氨基酸)潜力的小型开放阅读框(smORFs)。然而,实际翻译的smORFs数量及其分子和功能作用尚不清楚。
本研究中,作者通过对果蝇的多聚体(Polysome)部分进行核糖体分析(ribo-seq),从全基因组水平对smORFs翻译进行了评估。作者检测到两种类型的smORFs结合多个核糖体,从而进行活跃性翻译:
- “较长”smORFs大约编码80个氨基酸,在翻译度量和保守性方面类似于典型蛋白,并且可能包含跨膜基序;
- “较短”smORFs通常编码约20个氨基酸,主要存在于5'UTR和非编码RNA中,保守性较差,且没有肽功能。
本研究表明:数千个smORFs在后生动物基因组中被翻译,它们是基因组中一类丰富且基本的组成原件。
文章索引
标题:Extensive translation of small Open Reading Frames revealed by Poly-Ribo-Seq
发表期刊:eLife
发表时间:2014.08
作者团队:英国苏塞克斯大学生命科学学院Juan-Pablo Couso团队
IF:7.7/Q1
DOI:10.7554/eLife.03528.
研究概览
研究结果
果蝇基因组的注释中,预测smORFs编码基因的比例是其他后生动物基因组的两倍(约829个smORFs基因,占总数的4%)。但只有164个带注释的smORFs具有以下表明翻译或肽功能的特征:(1)GO分析表明其具有蛋白质功能;(2)与蛋白质组学实验中的肽匹配;(3)编码序列具有保守性(图1A)。
- “Poly-Ribo-Seq”技术:多聚体(Polysome)组分的核糖体分析
为了特异性地富集活性翻译含有单个smORFs的mRNA,作者考虑到了smORFs的有限长度(≤303 nt)可结合核糖体的特点。据报道,1个核糖体占据80 nt。因此在smORFs上,核糖体的最大数量为5(起始密码子上一个,每80 nt一个)。qPCR证实:与large polysome相比,small polysome中的smORFs mRNA更丰富(补充图1A),但这表明果蝇的smORFs可以被多达6个核糖体结合,这可能反映了核糖体更紧密的分布。
因此,作者选择分离Fraction 2-6以富集smORFs。这些small polysome也可以结合典型的较长ORF的mRNA,这些ORF不会被核糖体完全覆盖,因此翻译的水平低于最高水平(补充图2)。
作者分别对large polysome和small polysome部分进行核糖体分析,并将胞质mRNA进行RNA-seq作为对照。分析显示:Poly-ribo-seq捕获了活跃翻译区域,因为约80%的reads映射到典型蛋白质编码基因的编码序列,读取密度在起始密码子之前和终止密码子之后下降(图1C)。
作者还分析了翻译效率(TE,即核糖体足迹的RPKM /总mRNA的RPKM)。与5'-和3'-UTR相比,CDSs中所有带注释的蛋白质编码转录本的TE中位数明显更高(图1D),这表明“Poly-Ribo-Seq”定义了活性翻译区域。
- Poly-Ribo-Seq检测smORFs翻译
在第一次的Poly-Ribo-Seq实验中,共有191个带注释的smORFs被认为是翻译的。占S2细胞中转录的smORFs的约70%(图2D)。随后,作者对small polysome进行了重复实验,检测到224个smORFs的翻译(图2D)。因而,两次实验共检测到227个smORFs的翻译,占S2细胞中转录smORFs的83%(图2E)。在两个独立的Poly-Ribo-Seq实验中,核糖体密度的全基因组分布是强相关的(R2= 0.83),这表明Poly-Ribo-Seq具有很高的可重复性(图2B)。
第三次重复实验中,作者加入了去除rRNA的处理,因此增加了检测到的ORF总数,但只将推定翻译的smORFs数量增加了一个(图2D)。三个独立实验的结果高度重叠(图2D)。这些数据表明:在S2细胞中转录的274个smORFs中,有228个被翻译(83%),这与标准长度蛋白质编码ORF的翻译比例(81%)非常相似(图2E)。
- smORFs翻译的验证
检测小肽需要特定的肽组学方法。作者对S2细胞中大小为5-15 KDa的小蛋白进行质谱分析,以寻找smORFs肽(45-130 aa)。共检测到60个带注释的smORFs肽,其中40个在Peptide Atlas S2数据集中未检测到(图2F)。
接着,作者进行了肽标记转染实验。将smORFs编码序列的C端带上去掉了起始密码子的FLAG标记,因此任何FLAG信号都是smORFs翻译的结果。
转染S2细胞后,观察到12个smORFs的翻译,它们表现出一系列的翻译指标(图3A-B)。标记肽表现出不同的亚细胞定位,这表明不同的肽功能(图3A-B)。
- smORFs的其他来源
另外,还有上游短ORF (uORF)。作者在28,529个FlyBase注释转录本的11,587个5'UTR中鉴定出14,881个带有AUG起始密码子的uORF。其中9069个uORF在S2细胞中被转录,其中2708个(30%)被核糖体覆盖(图2E)。但它们编码肽的丰度较低。然而,uORF的标记偶尔会显示出与已标注的smORFs相似的信号(图3D)。
- 翻译smORFs的生物信息学分析揭示了其特定的特征
进一步地,作者研究了翻译后的smORFs的氨基酸组成,与常规长蛋白和氨基酸随机使用进行了比较(图4B)。注释的smORFs显示精氨酸的使用低于随机使用,也显示出几种氨基酸的不同使用,如富含赖氨酸和苯丙氨酸,而缺乏丝氨酸(图4B)。这些氨基酸是典型蛋白质中α -螺旋的特征。在翻译smORFs(图4C)和所有预测的smORFs中(图4D)均大约三分之一存有大量假定的跨膜α-螺旋基序。
Poly-Ribo-Seq检测到的翻译smORFs的生物信息学特征,包括:氨基酸用量(图4B)、推测的跨膜α -螺旋的丰度(图4C-D)和平均肽长度(图4E-F)。
由于uORF和ncRNA编码的肽在生物信息学上与smORFs和标准长CDS不同,因此暂时没有指标能够将翻译的uORF和ncRNA与基因间序列或随机序列区分开来。
因此,Poly-Ribo-Seq应该可以检测两种类型的smORFs的翻译:
- “较长”的smORFs,可以有效地翻译产生具有肽功能生物信息学标志的80个氨基酸;
- 从ncRNA和5 'UTR翻译而来的“短”smORFs,它们通常较短(~ 20aa),翻译效率较低,并且缺少此类生物信息学和分子标记。
研究结论
本研究表明:数千个smORFs在后生动物基因组中被翻译。而且,存在两种类型的翻译smORFs。“较长”的smORFs产生保守的80个氨基酸长的肽,其翻译效率类似于典型蛋白,其功能倾向于与细胞膜相关。“较短”smORFs主要存在于5'UTR和非编码RNA中,基因预测程序无法检测到,平均编码约20 aa长的肽。它们也不太保守,翻译效率较低,功能尚不清楚。
欢迎致电了解详情或咨询!
广州卿泽生物科技有限公司
地址:广州市黄埔区伴河路96号一栋三层321房
电话:18925086102(微信同号)
询价列表

暂时没有已询价产品

快捷询价 发送名片
当你希望让更多商家联系你时,可以勾选后发送询价,平台会将你的询价消息推荐给更多商家。